
Article by Sambhav Maheshwari and Karan Goel
Upon completing this article, you’ll have effortlessly forecasted the future multiple times. The headline alone gave you a rough idea of whether this article will pique your interest. Now, these initial lines serve as a litmus test, determining if the remainder merits your attention. We’re all natural forecasters with constant incentive to try to predict the future, be it in the pursuit of self-interested outcomes, or in the search for answers pertaining the future of humanity such as the development of emerging technologies, geo-political risk-analysis, or global development. Analyzing data from Metaculus, an online prediction market aimed to improve institutional decision-making, we find that large groups of forecasters are often very accurate yet tend to systematically overpredict low-probability outcomes while underpredicting high-probability outcomes.
Ever since Iowa Electronic Markets outperformed experts and polls in predicting election results from 1988 to 2004, the academic community has been particularly excited about leveraging the wisdom of crowds (Surowiecki, 2005), or how the “many are smarter than the few.” However, markets are frequently stymied by the multi-variable nature of a problem or sheer lack of data. Moreover, many remain skeptical of the prediction power in such markets and simply defer to experts when making their decisions, for example in recession forecasts, or more niche questions about the emergence of disruptive technologies. Are people justified in their skepticism of the crowd? Are there inherent patterns or trends in prediction markets of which a user ought to be aware?
To address these questions, we create two visualizations using data from Metaculus, an online forecasting platform and aggregation engine that brings together the global reasoning community and keeps score for thousands of forecasters, functioning as an active prediction market. Users are presented with a question and then allowed to assign a probability to the outcome of that binary event. An example could be, “will China launch a full-scale invasion of Taiwan by 2023?” People are expected to enter probability that the answer is “yes.” Aggregating responses using a median, Metaculus calculates the community prediction, which is indicative of what the “crowd” thinks. Because the predictions are probabilistic, it is not possible to say whether a given prediction was accurate or not. If the community predicted 90% chance of “yes” but the answer was “no”, was this a bad prediction or simply the one time in ten that the community believed was possible? Probabilistic predictions must be evaluated as a group. If the community assigns a 90% probability to each of 100 predictions, then these predictions are accurate if 90 of these questions to end up being “yes” and only 10 to end up being “no”.
We gather the predictions into groups based on the assigned probability. Those assigned a 0-5% chance are in one bin; 5-10% in the next, and so on. Our first visualization plots the fraction of those questions within each bin for which the answer ended up being “yes.” We also plot a perfect predictor line x=y, which shows the ideal case in which the community systematically accurately predicts the probability. That is, for those questions predicted at 35-40% likelihood, roughly 35-40% of them come true.
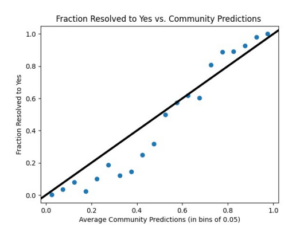
The data exhibits a clear consistency with prospect theory, which expects people to overpredict near-0-probability outcomes while underpredicting near-certain outcomes. There is a great deal of experimental evidence showing that people tend to round these near-extreme outcomes to the extremes. “Very unlikely” becomes “impossible” and “almost certain” becomes “certain”. The bins between 0-0.4, or the groups of questions where the median predictions were in the range of 0% to 40% show systematic overprediction. Essentially, if the average ‘median community prediction’ for a group of questions within a bin was 40%, the fraction that resolved to yes were much smaller, only around 20%. In bins between 70% to 100% people tend to, on average, overpredict. That is, they think the event is more likely to happen than it actually is. On average, across the bins, there is an underprediction of about 7%, driven by the questions that deal with low-probability outcomes.
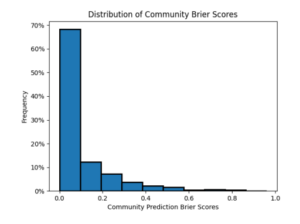
Our second visualization gives us a histogram of community Brier scores across 1793 binary Metaculus questions, illustrating the general accuracy of crowd prediction. A Brier score measures the accuracy of the average community predictions, and is computed as B=(p-f)^2, where f=1 if the event occurred, and f=0 if not. If you forecast 100% and an event occurred, your Brier score would be 0. If you forecast 100% and it did not occur, your score would be 1.
Predictions that lean neither one way or the other (50%) will automatically receive a Brier score of 0.25 no matter which outcome results. As a rule of thumb, smaller Brier scores indicate a more accurate prediction.
This histogram illustrates that community predictions are generally very accurate, with about 70% of the scores clustered from 0 to 0.1, exhibiting a positively skewed distribution.
In conclusion, we find that the wisdom of crowds is not free from human biases: the community median prediction shares some of the foibles of individual behavior. A wealth of experimental evidence demonstrates that individuals tend to underpredict low-probability outcomes, and somewhat overpredict outcomes that are highly likely to occur. Metaculus’ community median predictions share this same systematic bias. Nonetheless, on the whole, the community median is reasonably accurate, with an average Brier score of 0.091. This would mean predicting 70% on average for events that resolve to “yes”, and 30% for those that don’t. Thus, the community predictions are surely more accurate than most of us individuals. But it might be worthwhile to debias long-shot predictions before using them. Even the crowd is prone to exaggeration.